Method Overview
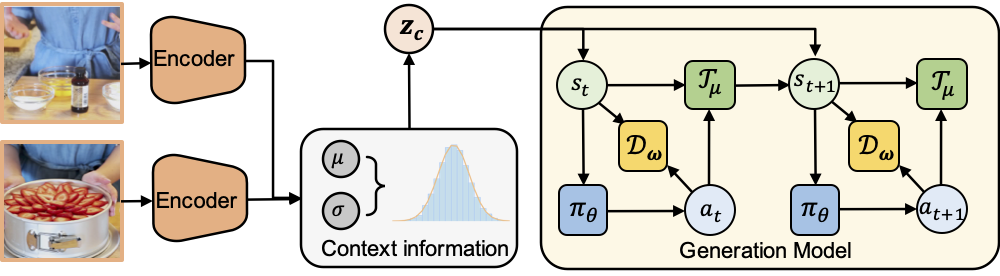
Overall architecture: given the initial and goal observations, two parallel encoders parameterize the mean and log-variance of the Gaussian distribution. The context variable is sampled from this distribution and fed into the generation model to roll out a trajectory.
Our method addresses the procedure planning problem by decomposing it into two sub-problems:
(1) inferring the time-invariant contextual information that conveys the task to achieve, and
(2) learning the time-varying plannable representations related to the decision-making process and environment dynamics.
We formulate procedure planning as p(a₁:T|o₁,oT) = ∬ p(a₁:T,s₁:T|zc)p(zc|o₁,oT)ds₁:T dzc, where zc is the context variable and p(a₁:T,s₁:T|zc) is the generation model.
Problem Formulation
Given a starting visual observation o₁ and a visual goal oT, we want to learn a plannable representation for two complex planning tasks:
• Procedure planning: generate a valid sequence of actions a₁:T to achieve the indicated goal
• Walk-through planning: retrieve the intermediate observations o₂:T-1 between the starting and goal states
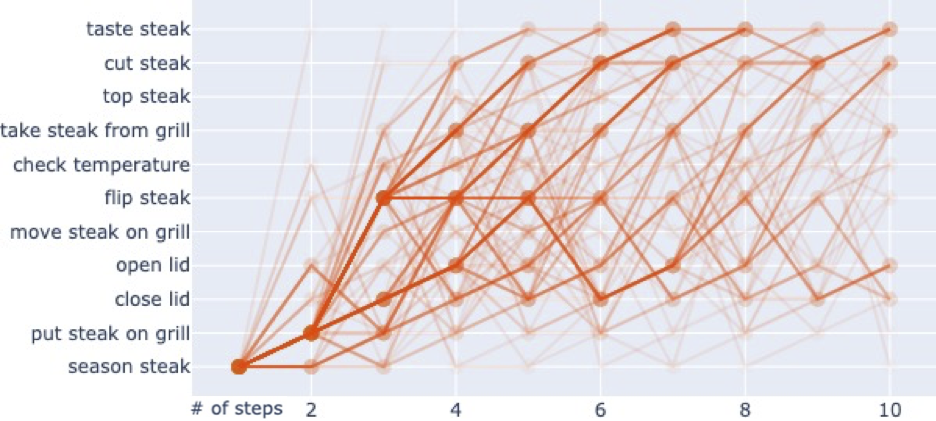
Expert trajectories of the "Grill Steak" task showing action sequence patterns. Heavier colors indicate more frequently visited paths. Our method learns to capture both short-term action separation (actions that can be interchanged) and long-term action association (actions that must occur in specific order relative to others).
region tokens. Attention is concentrated in specific layers, particularly in the early and middle
layers. Comparing visual and plain generative tasks, we observe that the bounding box does not alter the
attention head patterns. However, when comparing with a plain object prompt, including the object name
in the question prompt activates additional attention heads not triggered by the visual prompt,
suggesting that the attention heads exhibit dynamic activation based on the context—whether visual or
linguistic. This highlights their ability to adjust their function and behavior in response to changing
inputs. Further comparison between versions 1.6 and 1.5 demonstrates an improvement in image attention
across all layers in version 1.6. However, this pattern is not as evident in the 1.6 13B model. The
region token attention is omitted in 1.6 due to the more complex handling of the input image, making it
challenging to track bbox token indices. Additionally, we see that the visual prompt does not improve
the attention head’s focus on specific regions, as evidenced by comparing the first and second rows of
the heatmap.
Inference and Generation Models
Our approach consists of two main components:
• Inference Model: Uses variational inference to approximate the posterior distribution p(zc|o₁,oT) from given observations. We employ a predictive VAE structure that learns to embed contextual information distinguishing different tasks.
• Generation Model: Models the decision-making process as a Goal-conditioned MDP where actions depend on the current state and context variable. We propose two variants: Int-MGAIL (deterministic) and Ext-MGAIL (stochastic).
Model-based Imitation Learning
Instead of traditional model-free approaches, we incorporate a transition model to explicitly learn environment dynamics. This allows the policy to pursue goals by leveraging causal knowledge of actions' potential consequences, making it suitable for goal-directed behavior learning from static datasets without environment interaction.
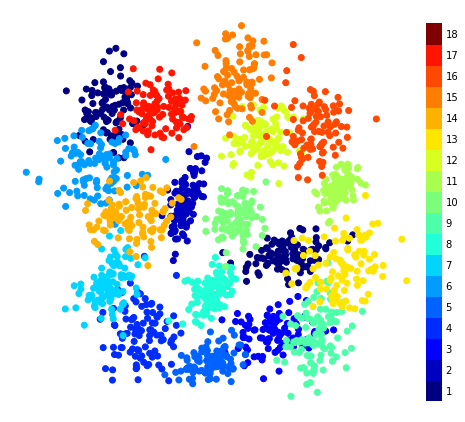
Visualization of the contextual information extracted from starting and goal observations of all 18 tasks in the CrossTask dataset. The colorbar indicates different tasks, showing that our inference model learns distinct regions in latent space for different tasks without using task labels during training.
Experimental Results
Based on our observations, we propose an enhanced metric to more effectively capture attention head behavior
across different datasets. Specifically, we recommend not only using attention weights but also
incorporating a concentration score as a complementary dimension. This concentration score quantifies how
narrowly or broadly a model head focuses on particular regions within an image as it processes each layer.
Together, these metrics form a two-dimensional representation that offers a more comprehensive view of the
model’s attention patterns.
Procedure Planning Results
We compare against several baselines including Universal Planning Networks (UPN) and Dual Dynamics Networks (DDN). Our methods significantly outperform all baselines:
Success Rate (T=3): Our Ext-MGAIL achieves 21.27% vs DDN's 12.18%
Accuracy (T=3): Our Ext-MGAIL achieves 49.46% vs DDN's 31.29%
mIoU (T=3): Our Ext-MGAIL achieves 61.70% vs DDN's 47.48%
The stochastic Ext-MGAIL outperforms the deterministic Int-MGAIL, showing that modeling uncertainty in action policy helps explore alternative valid action sequences for the same goal.
Walk-through Planning Results
For walk-through planning, our model needs to retrieve intermediate observations between start and goal. We construct a rank table to evaluate transition probabilities and find the optimal path. Results show our methods significantly outperform baselines:
Hamming Distance (T=3): Our Ext-MGAIL achieves 0.13 vs DDN's 0.26
Pair Accuracy (T=3): Our Ext-MGAIL achieves 93.66% vs DDN's 86.81%
Key Findings
Our experiments demonstrate several important findings:
- Contextual Information: The inference model learns distinct regions in latent space for different tasks without using task labels during training
- Model-based Learning: Incorporating transition models with policy learning significantly improves performance over model-free approaches
- Stochastic vs Deterministic: The stochastic Ext-MGAIL model better handles the inherent uncertainty in action sequences
- Hindsight Experience Replay: Data augmentation through relabeling consistently improves performance

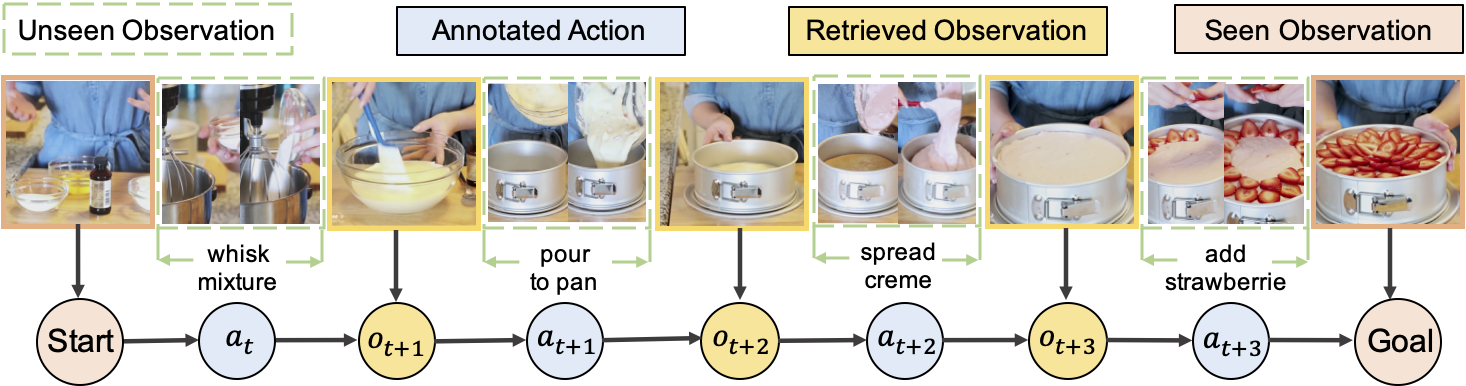
Walk-through Planning qualitative results for "Grill Steak". Given the starting and goal observations, our model can output the correct order for each step, successfully retrieving the intermediate observations that lead from the initial state to the desired goal.
Citation
If you found this work is useful in your own research, please considering citing the following.
@inproceedings{bi2021procedure,
title={Procedure Planning in Instructional Videos via Contextual Modeling and Model-based Policy Learning},
author={Bi, Jing and Luo, Jiebo and Xu, Chenliang},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
pages={5878--5887},
year={2021}
}